




July 2024 - current
Researcher at Tencent Youtu Lab, Shanghai
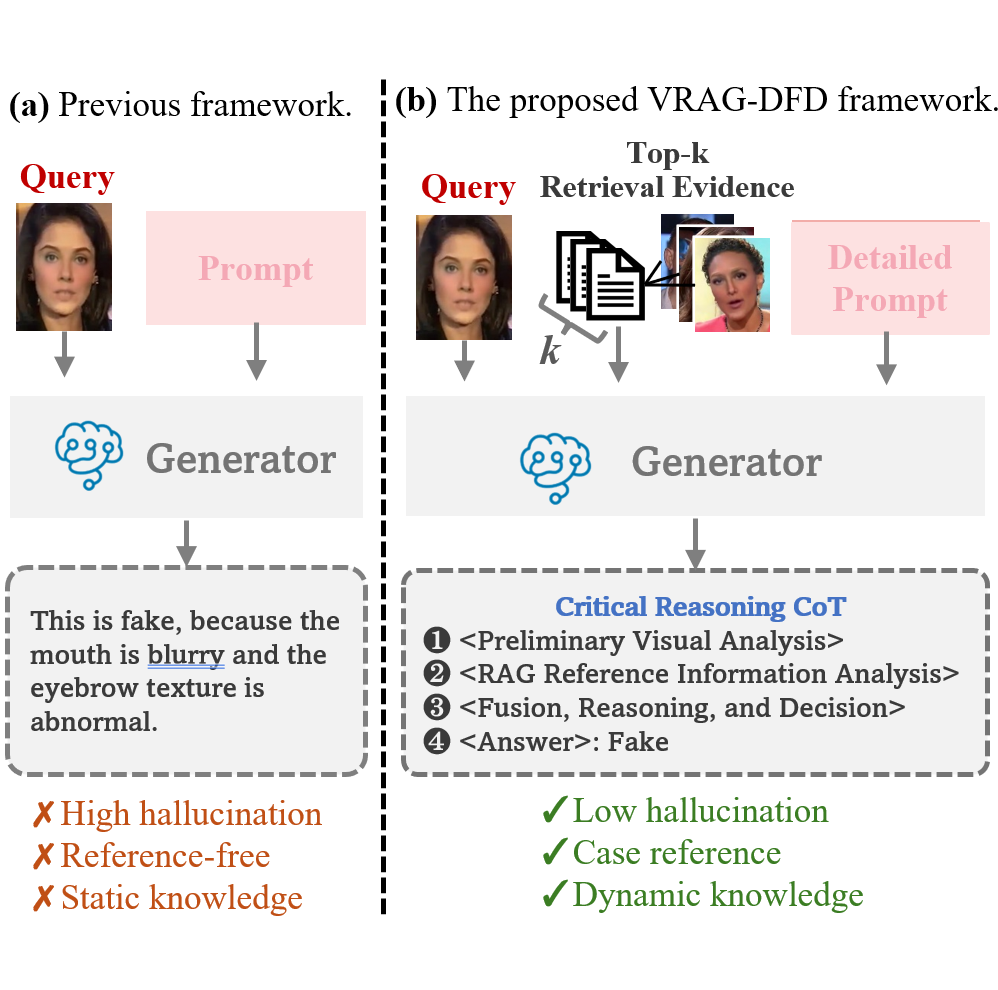
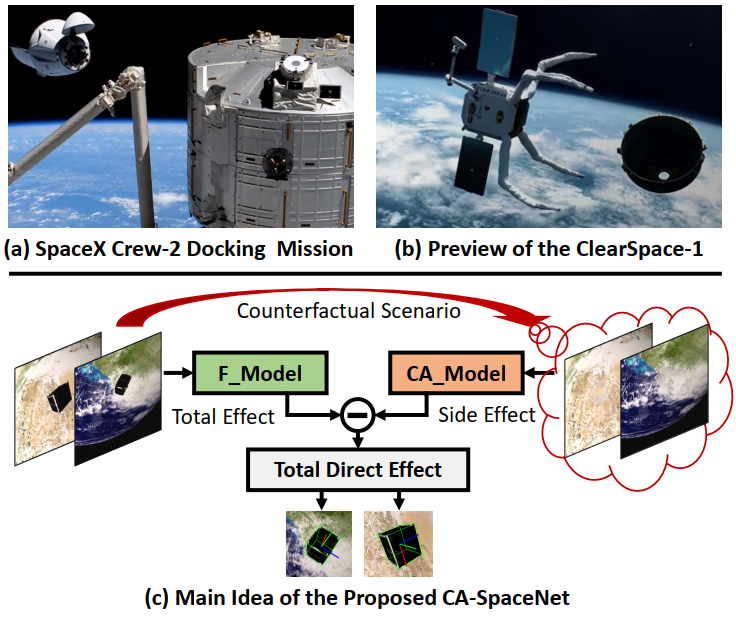
Research Topics: Deepfake detection and AIGC detection.
Sep 2019 - Jun 2024
PhD Student at Academy for Engineering and Technology, Fudan University, Shanghai
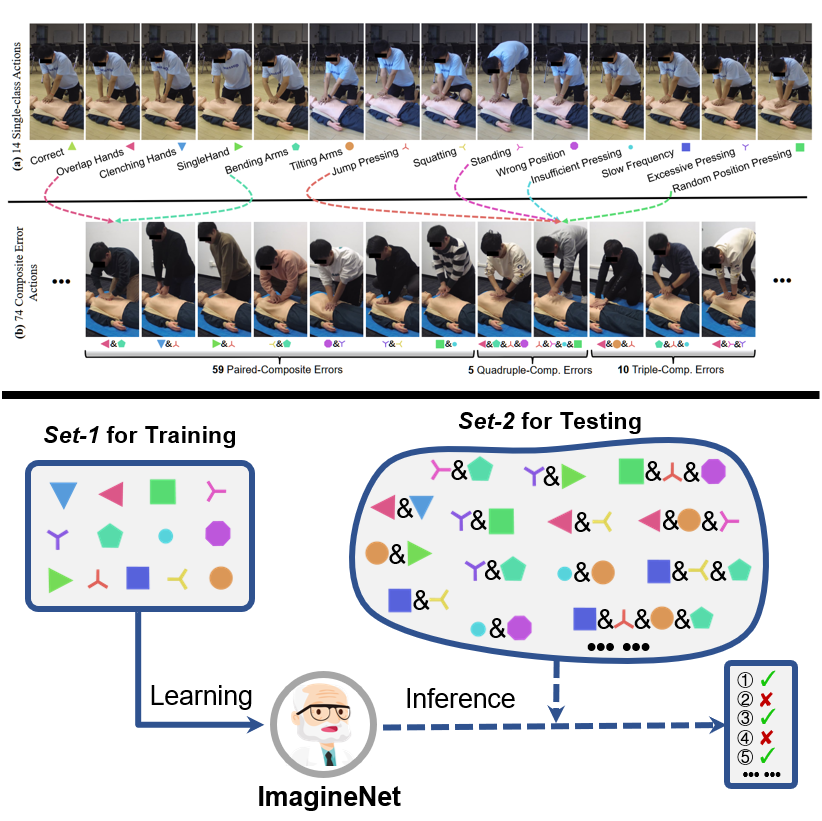
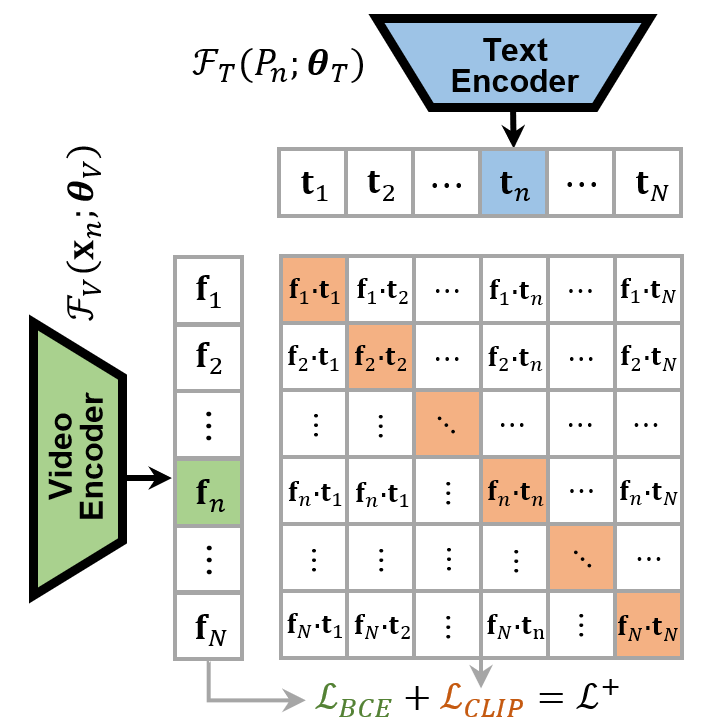
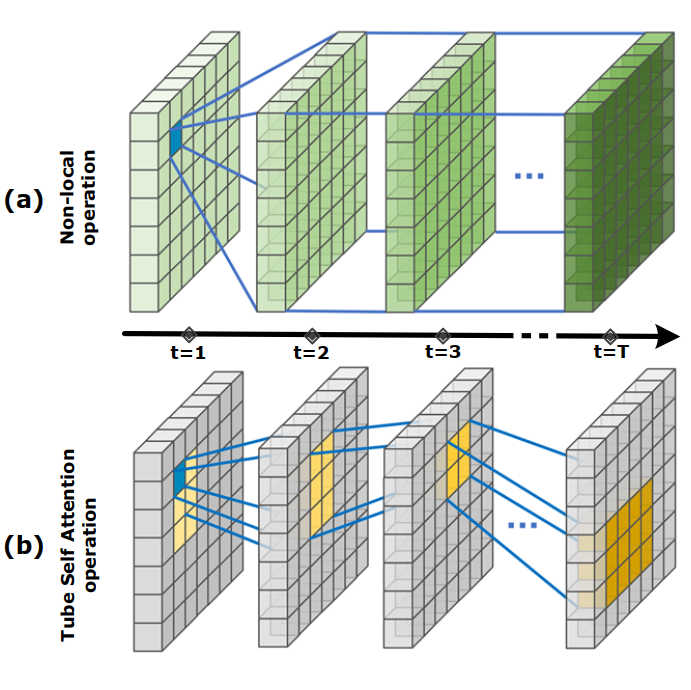
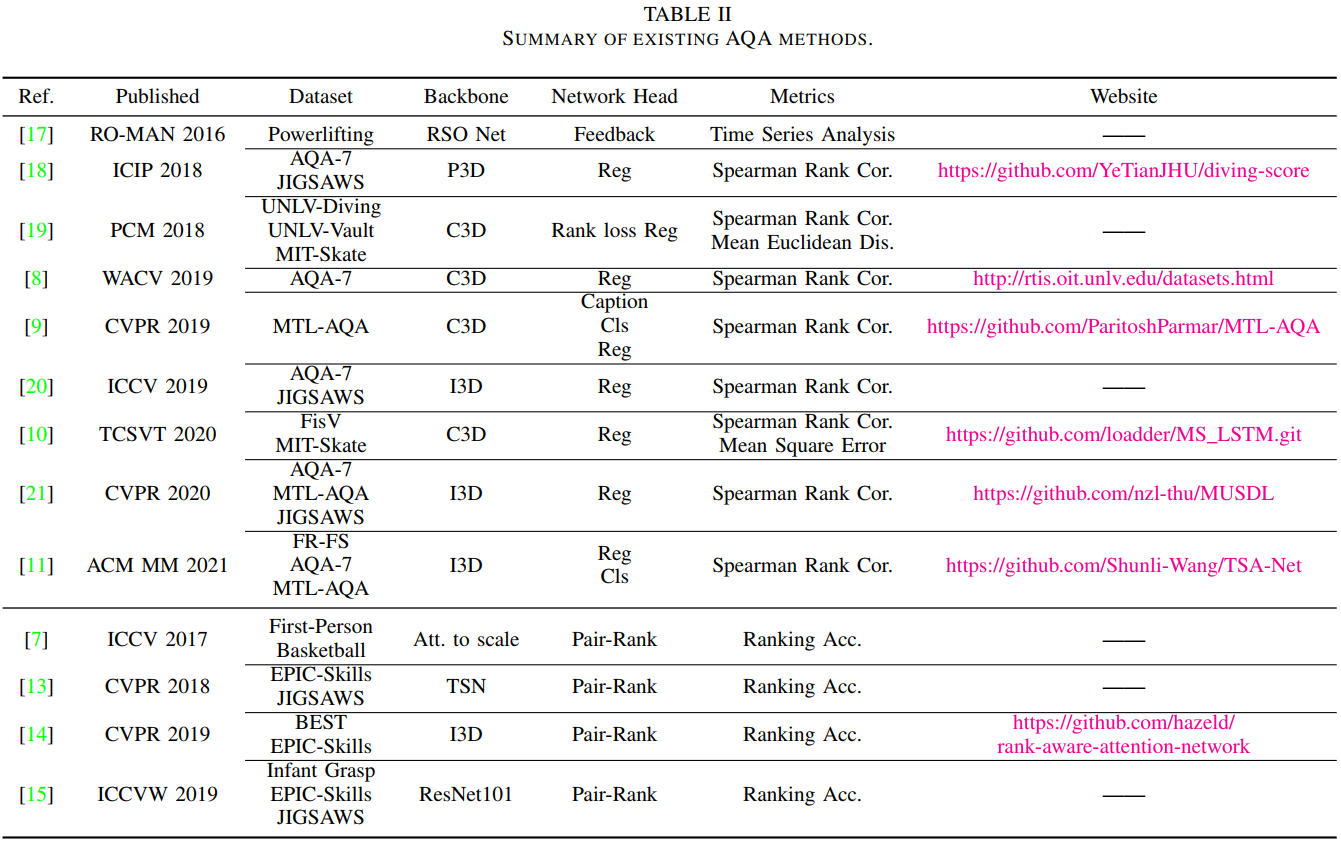
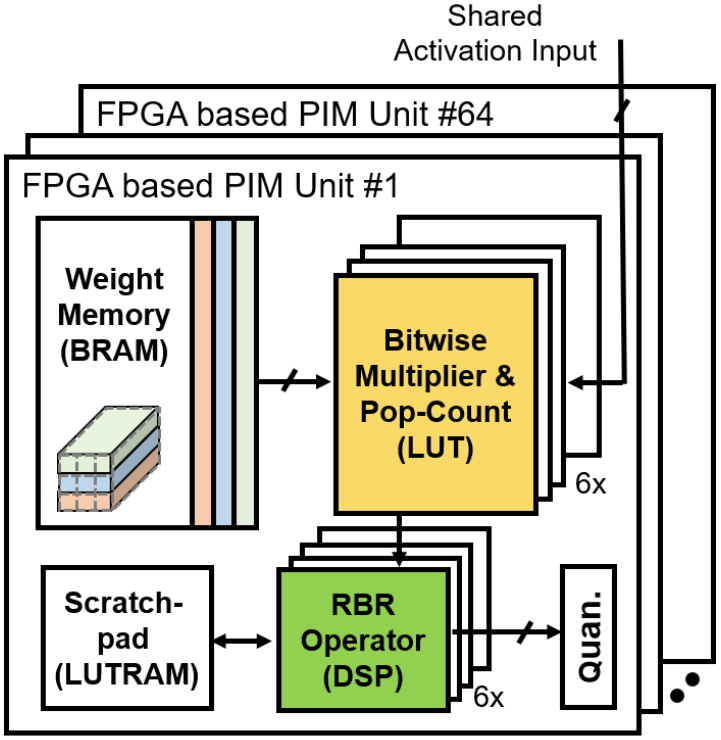
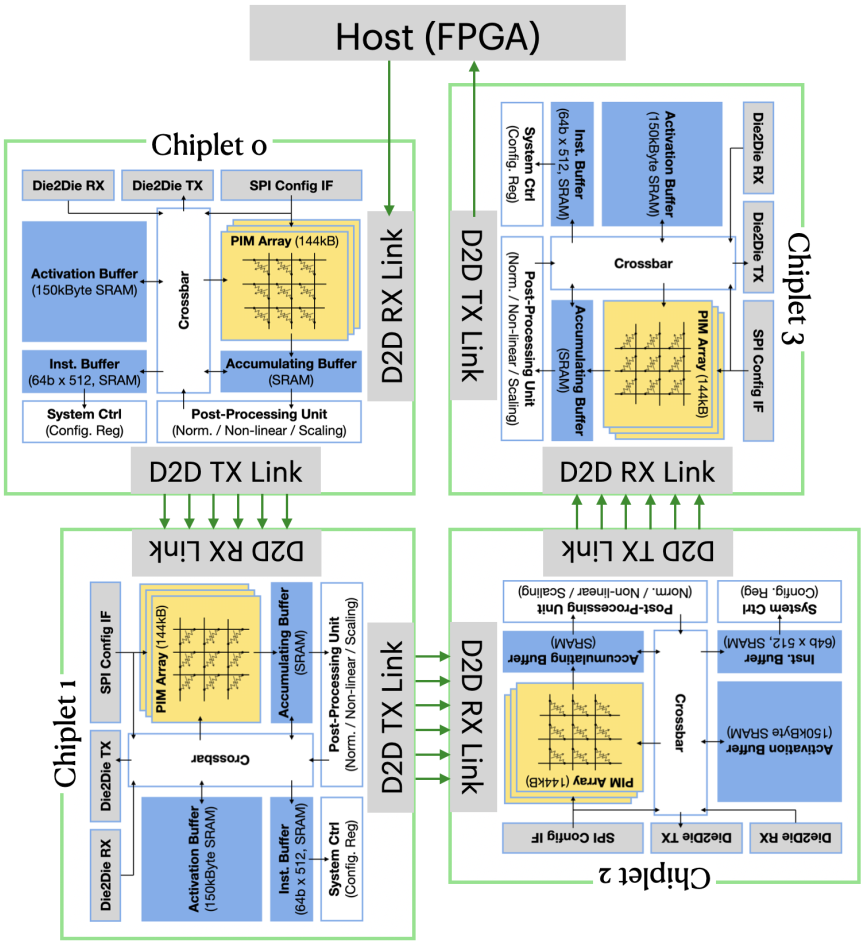
Research Topics: Fine-grained action recognition and action quality assessment in medical scenes.
Sep 2015 - Jun 2019
Bachelor's Degree, Anhui University
Thesis: Figure Skating Analysis System Based on Multi-target Tracking and Posture Estimation